| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 프레임워크
- ui
- Unity Editor
- 패스트캠퍼스
- 환급챌린지
- Job 시스템
- 가이드
- Framework
- 패스트캠퍼스후기
- RSA
- 커스텀 패키지
- 암호화
- 2D Camera
- adfit
- DotsTween
- Tween
- C#
- unity
- 샘플
- 오공완
- Custom Package
- TextMeshPro
- 최적화
- AES
- 직장인공부
- sha
- 직장인자기계발
- Dots
- base64
- job
- Today
- Total
EveryDay.DevUp
패스트캠퍼스 환급챌린지 54일차 : Part5. 강화학습 본문
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
https://bit.ly/4hTSJNB
커리어 성장을 위한 최고의 실무교육 아카데미 | 패스트캠퍼스
성인 교육 서비스 기업, 패스트캠퍼스는 개인과 조직의 실질적인 '업(業)'의 성장을 돕고자 모든 종류의 교육 콘텐츠 서비스를 제공하는 대한민국 No. 1 교육 서비스 회사입니다.
fastcampus.co.kr
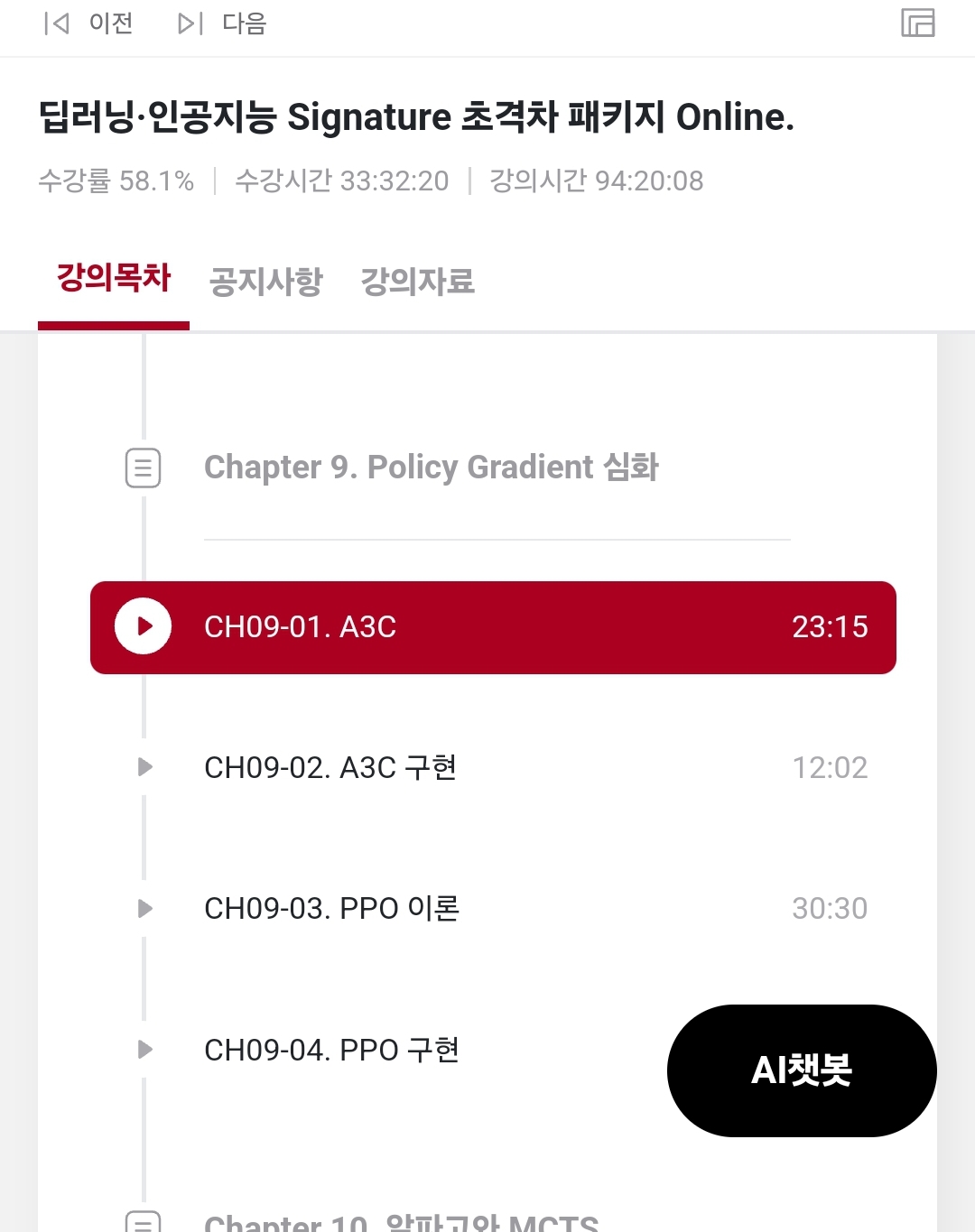
Chapter09. Policy Gradient 심화
Ch09-01 A3C
- Asynchornous Methods for Deep RL 논문
: 비동기적으로 경험을 쌓은 에이전트 (액터 러너 스레드)들이 있고, 각자의 경험을 중앙에 공유하는 시스템을 가짐
: 논문에서 다루는 4가지 알고리즘 중 Advantage Actor Critic 알고리즘이 좋은 성능을 보여줌
- Asynchornous Advantage Actor Critic을 줄여서 A3C라고 함
: 병렬적으로 advantage actor ciritic을 계산
: 중앙에서 최신 파라미터를 가져오고, 경험을 쌓은 뒤 가져온 파라미터를 업데이트하여 중앙에 전달함
: 학습에 걸린 시간이 DQN, WDQN 보다 적음
Ch09-02 A3C 구현
- 하이퍼 파라미터
: 학습 프로세스의 개수, 러닝 레이트, 업데이트 주기, 몇번 학습 시킬 것인가, 테스트는 몇번을 할 것인가를 정함
- 병렬적으로 처리하는 부분을 제외한 모델은 Actor Critic 모델과 동일함
- 중앙 프로세스 1개 + 학습 프로세스의 개수로 만들어짐
Ch09-03 PPO 이론
- Proximal Policy Optimaztion Algorithms
: 어느 환경에서든 성능이 안정적으로 나옴
-> 액션 스페이스가 컨티뉴어스하거나 액션 스페이스가 디스크릭트 한 곳에서든 안정적임
: 구현이 쉽기 때문에 버그의 요소가 적음
: 지금 얻은 데이터로 가능한 많은 지식을 뽑아내는 것을 목표로 하여, 현재 폴리시의 세터와 업데이트한 폴리시의 세터가 많이 달라지지 않게 하면서 업데이트하는 방법론을 사용함
- Original Loss와 Clipped Loss에서 작은 값을 사용함
Ch09-04 PPO 구현
- PPO 에서는 GA ( Generalized Advantage Esitimation) 을 사용하여 어드밴티리를 계산함